



ℹ️ Note: The images with plugin examples and the demo project were created using the Runtime Audio Importer plugin. So, to follow these examples, you will need to install that plugin as well. However, you can also implement your own audio input solution without using it.
🗣️ Transform your game with real-time, offline, cross-platform text-to-speech synthesis! No internet, no subscriptions, no privacy risks.
Add powerful offline text-to-speech capabilities to your project with 39 languages and 900 voices featuring more than 160 voice qualities. Synthesize speech in real-time without internet connectivity, powered by Piper, Kokoro and ONNX Runtime.
🚀 New! Now featuring Kokoro voice models – high-quality, open-source TTS architectures with studio-level voice synthesis. Includes 45 models across 6 languages, offering natural and expressive speech output.
Quick links:
Key features:
🎯 Core Capabilities:
- Complete offline text-to-speech synthesis
- 40 languages supported
- 900+ unique voices available
- 120+ voice qualities
- Cross-platform support: Windows, Linux, Mac, Android (including Meta Quest), iOS
- Experimental support for Apple Vision Pro
⚡ Voice System:
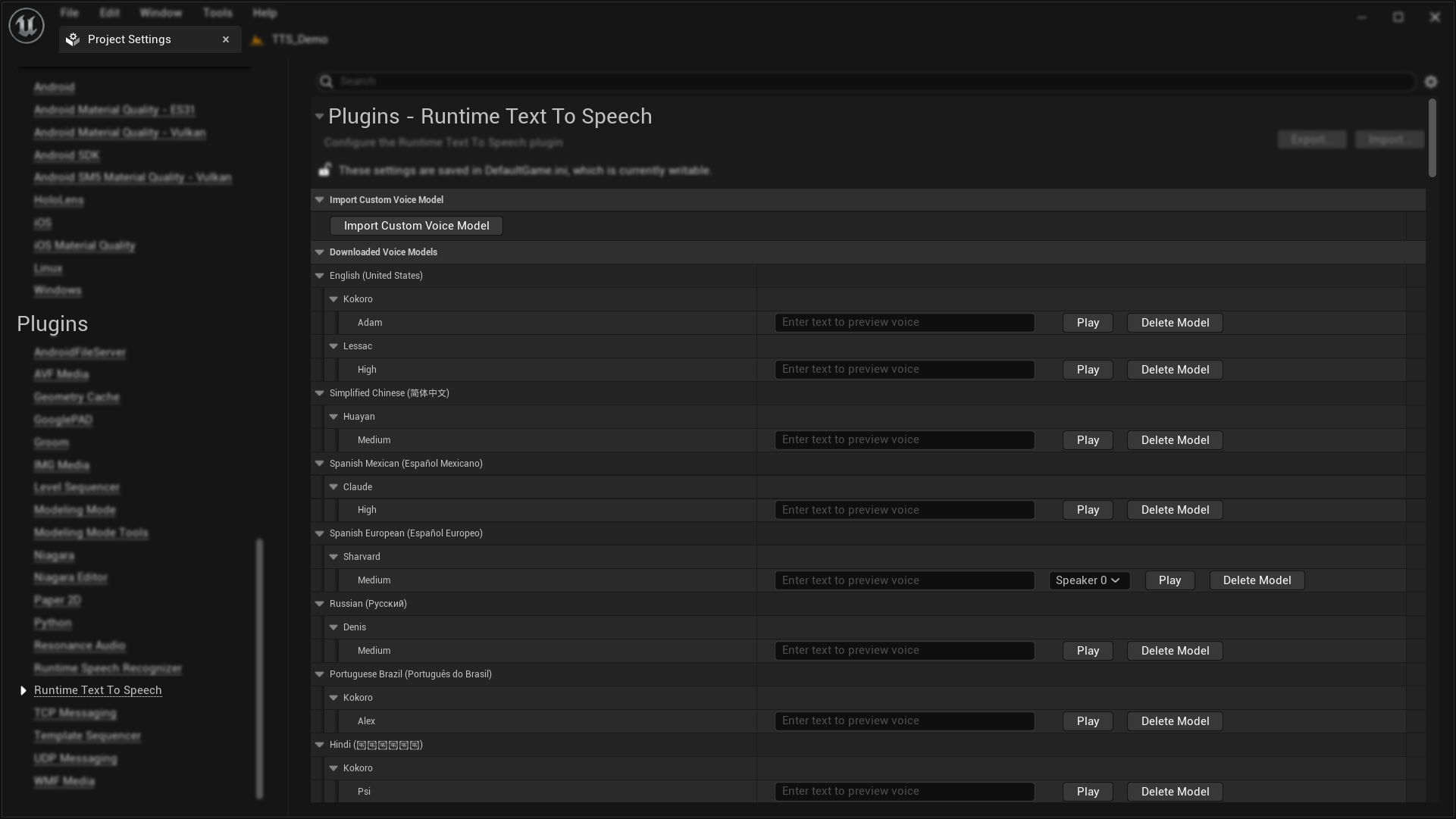
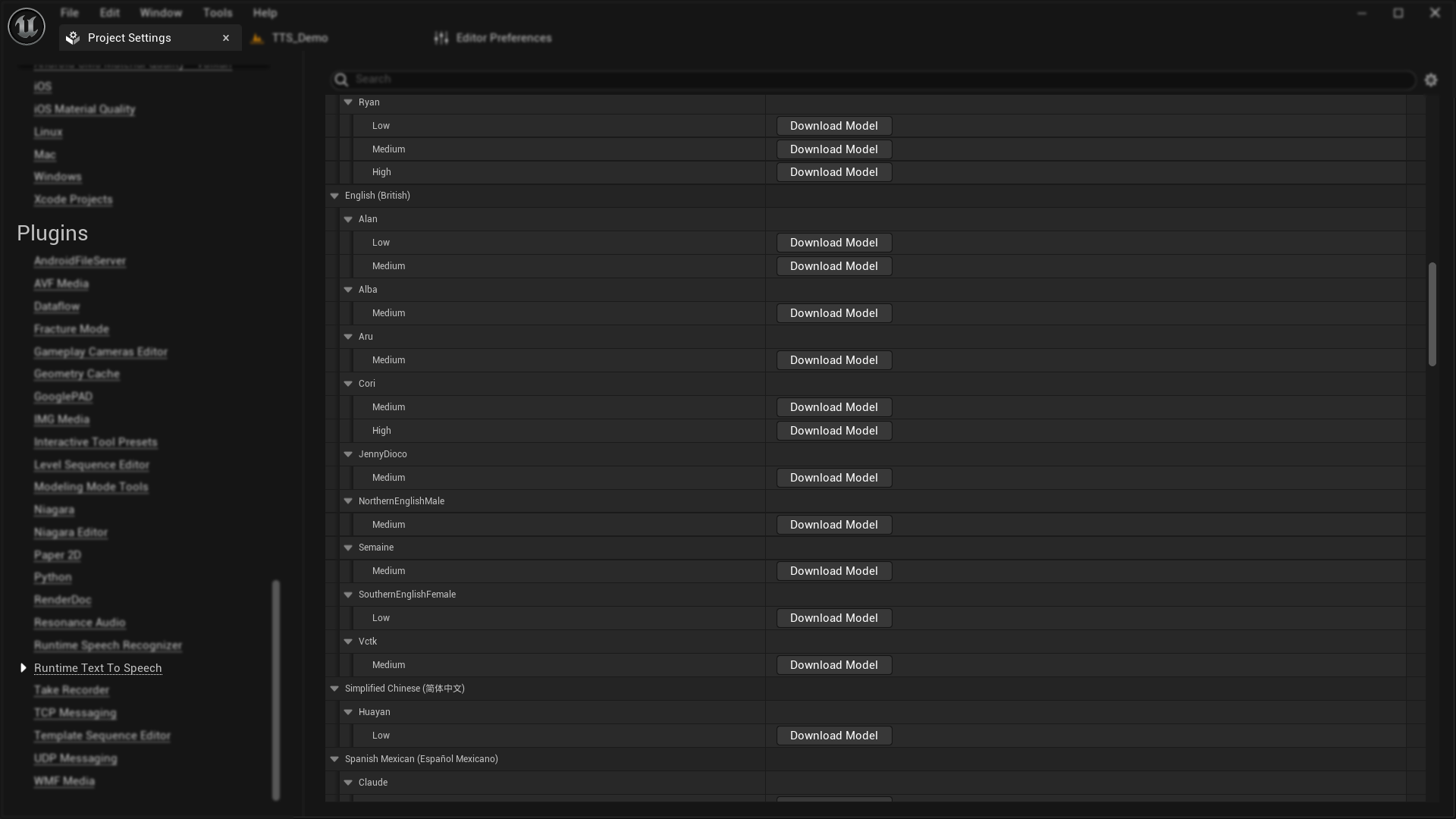
- One-click voice model downloads through editor interface
- In-editor voice preview and testing
- Runtime voice model selection
- Raw PCM float audio output
- Flexible integration with any audio playback solution
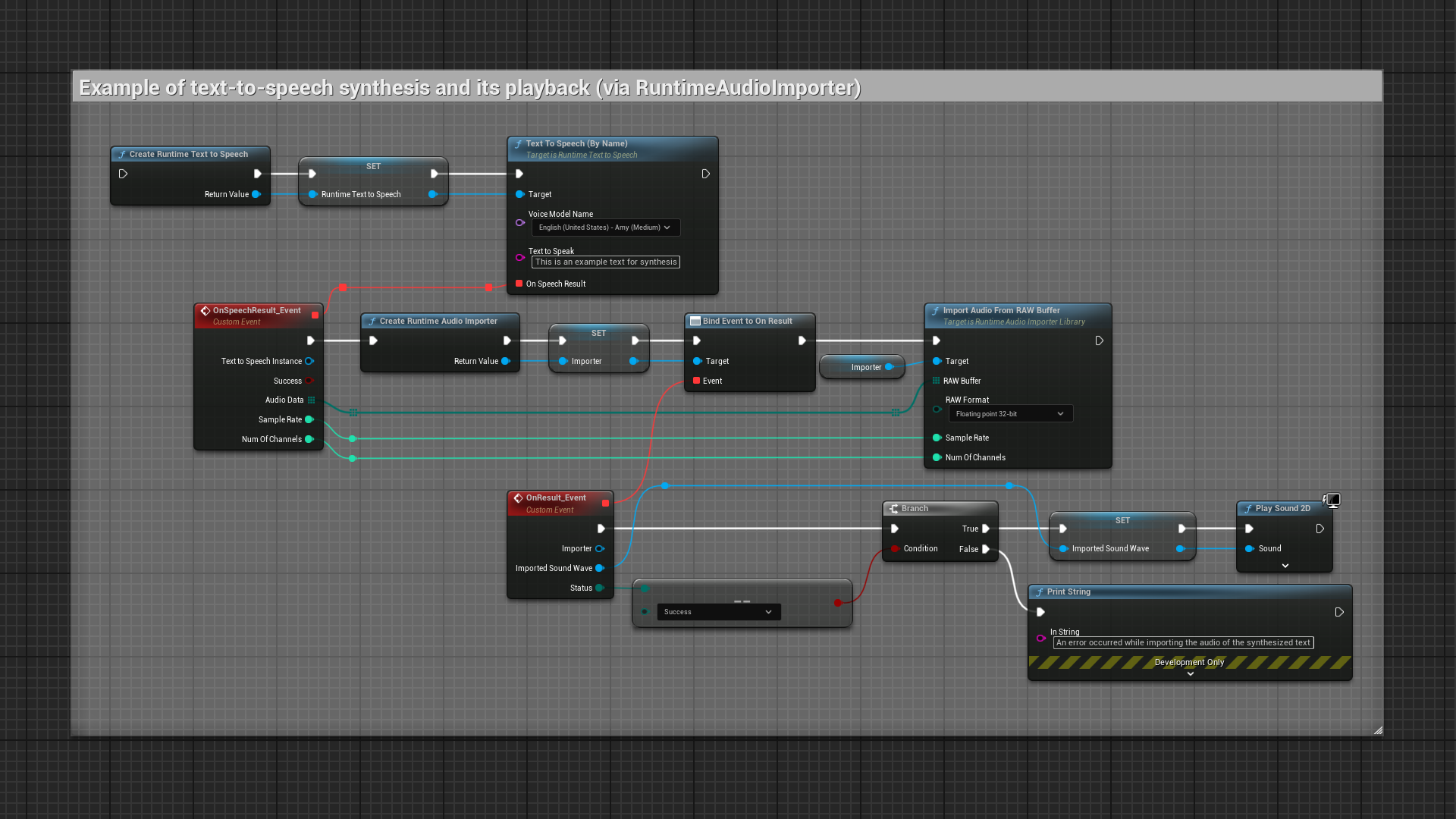
- Built-in compatibility with Runtime Audio Importer
🛠️ Development Features:
- Full Blueprint and C++ API support
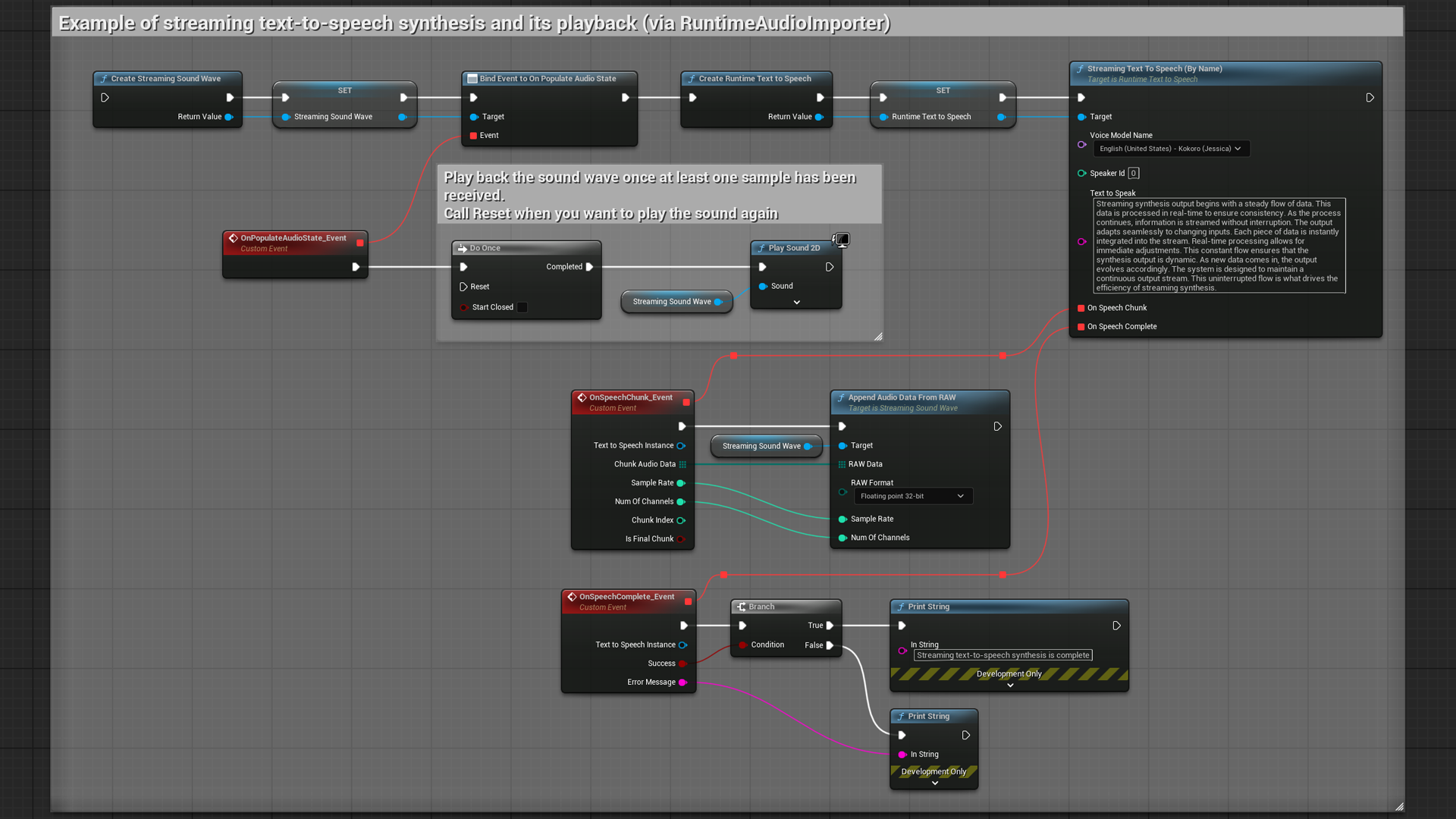
- Regular and streaming synthesis modes
- Real-time audio chunk processing
- Synthesis cancellation support
- Easy voice model management and packaging
- Comprehensive voice metadata access
- Simple voice model selection via dropdown
- Automated voice model packaging with projects
🌍 Supported languages:
Some voice models also support multiple speakers, which significantly increases the variety of available voices – for example, English LibriTTS alone includes more than 900 different speakers.
- 🇺🇸 English (United States) – 19 voice models, 43 qualities (with Kokoro models)
- 🇬🇧 English (British) – 10 voice models, 19 qualities (with Kokoro models)
- 🇨🇳 Simplified Chinese (简体中文) – 2 voice model, 10 qualities (with Kokoro models)
- 🇲🇽 Spanish (Mexican / Español Mexicano) – 6 voice models, 8 qualities
- 🇪🇸 Spanish (European / Español Europeo) – 5 voice models, 5 qualities (with Kokoro models)
- 🇰🇷 Korean (한국어) – 1 voice model, 1 quality
- 🇷🇺 Russian (Русский) – 4 voice models, 4 qualities
- 🇧🇷 Portuguese (Brazil / Português do Brasil) – 3 voice models, 5 qualities (with Kokoro models)
- 🇵🇹 Portuguese (Portugal / Português de Portugal) – 1 voice model, 1 quality
- 🇮🇳 Hindi (हिन्दी) – 1 voice model, 4 qualities (with Kokoro models)
- 🇩🇪 German (Deutsch) – 8 voice models, 10 qualities
- 🇫🇷 French (Français) – 7 voice models, 8 qualities (with Kokoro models)
- 🇹🇷 Turkish (Türkçe) – 3 voice models, 3 qualities
- 🇵🇱 Polish (Polski) – 4 voice models, 4 qualities
- 🇮🇹 Italian (Italiano) – 3 voice models, 4 qualities
- 🇺🇦 Ukrainian (Украї́нська мо́ва) – 2 voice models, 2 qualities
- 🇦🇩 Catalan (Català) – 2 voice models, 3 qualities
- 🇨🇿 Czech (Čeština) – 1 voice model, 2 qualities
- 🏴 Welsh (Cymraeg) – 1 voice model, 1 quality
- 🇩🇰 Danish (Dansk) – 1 voice model, 1 quality
- 🇬🇷 Greek (Ελληνικά) – 1 voice model, 1 quality
- 🇮🇷 Farsi (فارسی) – 2 voice models, 2 qualities
- 🇫🇮 Finnish (Suomi) – 1 voice model, 1 quality
- 🇭🇺 Hungarian (Magyar) – 3 voice models, 3 qualities
- 🇮🇸 Icelandic (Íslenska) – 4 voice models, 4 qualities
- 🇬🇪 Georgian (ქართული ენა) – 1 voice model, 1 quality
- 🇰🇿 Kazakh (Қазақша) – 3 voice models, 3 qualities
- 🇱🇺 Luxembourgish (Lëtzebuergesch) – 1 voice model, 1 quality
- 🇱🇻 Latvian (Latviešu) – 1 voice model, 1 quality
- 🇳🇵 Nepali (नेपाली) – 1 voice model, 2 qualities
- 🇧🇪 Dutch (Belgium / Vlaams) – 2 voice models, 4 qualities
- 🇳🇱 Dutch (Netherlands / Nederlands) – 3 voice models, 3 qualities
- 🇳🇴 Norwegian (Bokmål / Nynorsk) – 1 voice model, 1 quality
- 🇷🇴 Romanian (Română) – 1 voice model, 1 quality
- 🇸🇰 Slovak (Slovenčina) – 1 voice model, 1 quality
- 🇸🇮 Slovenian (Slovenščina) – 1 voice model, 1 quality
- 🇷🇸 Serbian (Srpski) – 1 voice model, 1 quality
- 🇸🇪 Swedish (Svenska) – 1 voice model, 1 quality
- 🇰🇪 Swahili (Kiswahili) – 1 voice model, 1 quality
- 🇻🇳 Vietnamese (Tiếng Việt) – 3 voice models, 3 qualities
🎮 Perfect for:
- Accessible game interfaces
- Dynamic NPC conversations
- Voice-driven tutorials and hints
- Procedurally generated content
- Localization solutions
- Assistive technologies
- Interactive storytelling
- Educational applications
You can contact us at any time and request that the asset you want be added to the site from the Request Asset section.
